Task Distribution
Task distribution is a crucial step that occurs after the selection process, where a group of devices that meet the nnApp's criteria is chosen. The objective of task distribution is to effectively allocate tasks in a pseudo-randomized manner among a selected set of workers, while also ensuring a balanced workload and respecting resource constraints.
To achieve this goal, the algorithm employs a Greco-Latin square (opens in a new tab) distribution approach, which evenly distributes tasks across computers while considering the available resources of each device. By doing so, the algorithm achieves two key objectives: maintaining a balanced workload across all workers and optimizing resource utilization by considering compatibility with the available resources on each computer.
Task Distribution Algorithm
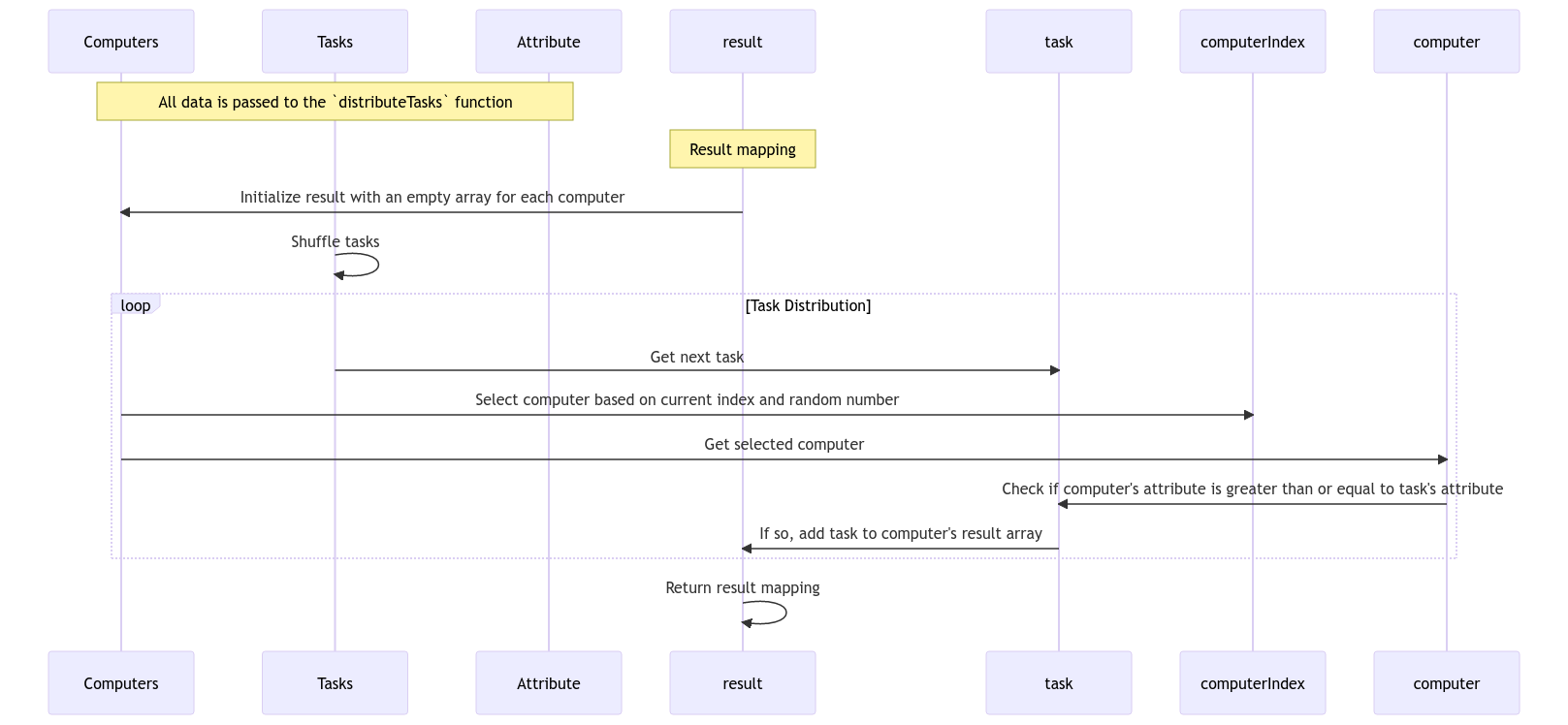
The task distribution process involves three key elements:
- a list of tasks to be executed
- the specific requirements for each task
- the chosen nodes from the node selection process
Utilizing a Greco-Latin square distribution method, the algorithm starts by initializing an empty array for each selected node, designated to hold the tasks it will carry out.
The algorithm iteratively assesses each task's compatibility with available computers based on resources. It enters a loop, selecting tasks from a shuffled list and randomly assigning them to a computer. If a task's attribute requirement is less than or equal to the computer's attribute, the task is added to the computer's task array. The loop continues until all tasks are assigned, ultimately yielding a mapping or matrix outlining each computer's assigned tasks.
As a final step, the algorithm consolidates the distribution matrix into a result object, providing both the allocated tasks and any tasks that remain in the queue.
Overall, this method allows for efficient task distribution to computers, ensuring a balanced workload and accommodating resource limitations.
Matrix Construction
Given n computers, let M be an n x n matrix defined as follows:
, where and
Each element represents a list of tasks. To apply the algorithm, follow these steps:
- For each task in the tasks list, evaluate its compatibility with the current computer .
- A task is deemed compatible if, for all attributes () and corresponding values (), the computer's attribute value is greater than or equal to the task's attribute value:
- If the task is compatible, append it to the matrix's corresponding row and column based on the current row index:
- If the task is incompatible, add it to a list of queued tasks.
- Increment the current row index, wrapping around when necessary:
- Flatten the matrix and return the distributed tasks along with the queued tasks as a tuple, ensuring a comprehensive and robust distribution of tasks.